
Dror just sent me some background on his two new very interesting preprints:
Hey Igor - ....
I'm writing about two two recent related papers, and I wanted to give you a heads up about them. I'm also copying all the coauthors.
The first paper is a conference paper by all four of us (Puxiao Han, Junan Zhu, myself, and Ruixin Niu), and it will appear on ICASSP in March. The second is a journal submission by Junan Zhu and myself.
The topic is approximate message passing (AMP) with multiple processors (MP-AMP), which is intended to solve large scale signal recovery problems. It could also be used to learn linear models underlying data, of course. One challenge with past versions of MP-AMP is that the processors need to exchange messages, and this communication can be costly. Imagine, for example, running a huge signal recovery problem on several server farms in parallel, and needing to swap messages between locations. This communication slows down the process and is costly. To reduce the communication costs, we apply lossy compression to the messages. Following some optimizations with dynamic programming, we often get really nice reconstruction with only 2 or even 1.5 bits per number being communicated, on average. Contrast this to 32 bit per single precision floating point (not to mention double precision), and you'll see that this is a nice reduction. Our impression from some case studies is that communication costs (prior to optimizing them) can be larger than computational costs in some of these applications, and reducing them 10x can really reduce system-wide costs.One insight that comes out of the numerical results is that it's better to spend very few bits (a low coding rate) on early iterations of AMP, because in those early iterations the estimation quality is very noisy, and spending lots of bits to encode a junky estimate is basically still junk. In contrast, after several AMP iterations the quality improves, and it becomes more useful to invest in encoding these estimates at improved fidelity. That is, the coding rate per iteration tends to increase.If you have any questions or comments, we'll be glad to discuss!
Thanks Dror !
Here are the two preprints:
Multi-Processor Approximate Message Passing with Lossy Compression by Junan Zhu, Dror Baron
We consider large-scale linear inverse problems in Bayesian settings. Our general approach follows a recent line of work that applies the approximate message passing (AMP) framework in multi-processor (MP) computational systems by storing and processing a subset of rows of the measurement matrix along with corresponding measurements at each MP node. In each MP-AMP iteration, nodes of the MP system and its fusion center exchange messages pertaining to their estimates of the input. Unfortunately, communicating these messages is often costly in applications such as sensor networks. To reduce the communication costs, we apply lossy compression to the messages. To improve compression, we realize that the rate distortion trade-off differs among MP-AMP iterations, and use dynamic programming (DP) to optimize per-iteration coding rates. Numerical results confirm that the proposed coding rates offer significant and often dramatic reductions in communication costs. That said, computational costs involve two matrix vector products per MP-AMP iteration, which may be significant for large matrices. Therefore, we further improve the trade-off between computational and communication costs with a modified DP scheme. Case studies involving sensor networks and large-scale computing systems highlight the potential of our approach.
Multi-Processor Approximate Message Passing Using Lossy Compression by Puxiao Han, Junan Zhu, Ruixin Niu, Dror Baron
In this paper, a communication-efficient multi-processor compressed sensing framework based on the approximate message passing algorithm is proposed. We perform lossy compression on the data being communicated between processors, resulting in a reduction in communication costs with a minor degradation in recovery quality. In the proposed framework, a new state evolution formulation takes the quantization error into account, and analytically determines the coding rate required in each iteration. Two approaches for allocating the coding rate, an online back-tracking heuristic and an optimal allocation scheme based on dynamic programming, provide significant reductions in communication costs.
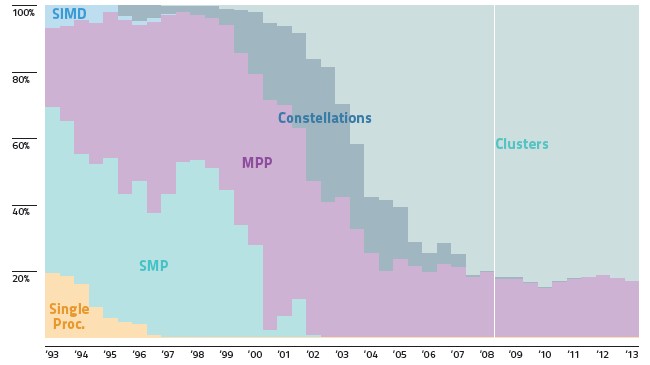
Why is this type of approach important ? Well, here is one figure from Timothy Prickett Morgan's Top500: Supercomputing sea change incomplete, unpredictable
 Liked this entry ? subscribe to Nuit Blanche's feed, there's more where that came from. You can also subscribe to Nuit Blanche by Email, explore the Big Picture in Compressive Sensing or the Matrix Factorization Jungle and join the conversations on compressive sensing, advanced matrix factorization and calibration issues on Linkedin.
Liked this entry ? subscribe to Nuit Blanche's feed, there's more where that came from. You can also subscribe to Nuit Blanche by Email, explore the Big Picture in Compressive Sensing or the Matrix Factorization Jungle and join the conversations on compressive sensing, advanced matrix factorization and calibration issues on Linkedin.
No comments:
Post a Comment