I have been asked
this question several times by colleagues and friends, so I decided to use my talents in Microsoft Paint to try to provide an explanation with some beautifully handcrafted pictures.
The problem to solve is the following: Let's say you have only
one sensitive pixel/photodetector/radiation detector/Teraherz detector at your disposal but you need to take a 10 Megapixel image like the one you can get from a Best Buy or an Amazon
point-and-shoot cameras
how would you go about it ? There are many ways to do this but let us also imagine that you can also put your hands on a DMD chip that is made of 10 million oscillating mirrors (an example include the famous
Texas Instrument DMD) like the ones you can find in digital projectors and you can command the action of each and everyone of these tiny (15 micrometer by 15 micrometer) mirrors. In other words, with a proper set-up, every milliseconds, you can decide to shine each of these mirrors on your detector .... or not. There are now two options for obtaining this 10MP image.
First option (the raster mode):
The raster mode is simple. Just shine one mirror at a time onto the detector and let all the other mirros shine elsewhere. Do this once

twice (with another mirror)

thrice (with yet another mirror)

four times (....)

five times (...)

....5 millions times (...)

until you reach the last 10 millionth mirror.

After doing all this, you now have ten million information which put together piece by piece provides you with a 10 MP image. Generally, you then use a small CPU to perform the Discrete Cosine Transform so that eventually you are now the proprietor of a JPEG image (i.e. a compressed version of this 10MP image).
Second option (the Compressive Sensing mode):
You tell the set of mirrors, on that DMD chip, to display a set of random tilings. That way, a random set of mirrors are shining the incoming light unto the detector.
You do this once with an initial random tiling and obtain your first CS measurement
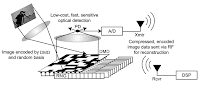
then you do this again with a second random tiling,
in order to obtain your second CS measurement

then you do this again with a third random tiling,
this is your third CS measurement

and so on.
Compressed sensing tells you that with very high probability, you will get the same result as the raster mode (first method) above but with many fewer CS measurements than the 10 million raster mode measurements obtained in the first method. In fact, instead of taking 10 million raster mode measurements, you are likely to need only 20 percent of that in the form of CS measurements, maybe even less.
The reason this second method works stems from the idea that most natural images are sparse in bases ranging from cosines,
wavelets to curvelets (this is also why JPEG does a tremendous job in decreasing the size of most images).
Functions that represent random tilings of reflective and non reflective mirrors (0s and 1s) are said to be mathematically "incoherent" with these bases thereby allowing an automatic compression at the detector level (here in the second mode, there is no need for compression with JPEG at the very end since the CS measurements are already compressed version of the image). A computational steps is required to obtain a human viewable image from these CS measurements. That step uses
these solvers.
What are the pros and cons of the second option compared to the first one ?
Pros:
- The overall sensor requires very low power because there is no CPU/GPU/FPGA trying to perform the compression stage at the very end (JPEG).
- The sensor is dedicated to acquiring information. Information processing can be done somewhere else ( think on some other planet)
- Compared to raw images (raster mode output), the information to be transmitted is very much compressed albeit not optimally (compared to JPEG).
- Instead you can spend all your money designing the very best sensitive pixel you want, it may even act as a spectrometer (looking at many different energy bands), radiation detector and so forth.
- Last but not least, the amount of light that goes to the detector is about half of the 10 million mirrors, which is quite high compared to the single mirror exposure in the raster mode (first method). In other words, the signal to noise ratio is pretty high (a good thing) in the CS mode as opposed to the raster mode.
Cons:
- Faint signals could be submerged in the CS measurements. You first need to have a high signal to noise ratio signal to detect small signals.
- Your sensor has to have a much larger dynamic range than in the raster mode in order for the A/D quantization algorithm to not mess with the CS measurements.
- The number of CS measurements will be higher than the number of bits required to store the JPEG of the raster mode (about 4 to 5 times higher). Then again (and this is a pro-argument, the transformation from raster mode to JPEG is the power hungry stage of your camera and the reason you always need to recharge it, memory on the other hand is cheap.)
Terry Tao provides a much clearer mathematical explanation albeit with no beautifully hand crafted images such as the ones found here. All information about this single pixel camera system can be found at
Rice University.
[ Update 2013:
Inview Corporation develops single pixel cameras using the intellectual property from Rice University ]












