: We develop a principled way of identifying probability distributions whose independent and identically distributed (iid) realizations are compressible, i.e., can be approximated as sparse. We focus on the context of Gaussian random underdetermined linear regression (GULR) problems, where compressibility is known to ensure the success of estimators exploiting sparse regularization. We prove that many priors revolving around maximum a posteriori (MAP) interpretation of the $\ell^1$ sparse regularization estimator and its variants are in fact incompressible, in the limit of large problem sizes. To show this, we identify non-trivial undersampling regions in GULR where the simple least squares solution almost surely outperforms an oracle sparse solution, when the data is generated from a prior such as the Laplace distribution. We provide rules of thumb to characterize large families of compressible (respectively incompressible) priors based on their second and fourth moments. Generalized Gaussians and generalized Pareto distributions serve as running examples for concreteness.
The background clutter has been becoming one of the most important factors affecting the target acquisition performance of electro-optical imaging systems. A novel clutter metric based on sparse representation is proposed in this paper. Based on the sparse representation, the similarity vector is defined to describe the similarity between the background and the target in the feature domain, which is a typical feature of the background clutter. This newly proposed metric is applied to the search_2 dataset and the experiment results show that its prediction correlates well with the detection probability of observers.
A collaborative convex framework for factoring a data matrix X into a non-negative product AS, with a sparse coefficient matrix S, is proposed. We restrict the columns of the dictionary matrix A to coincide with certain columns of the data matrix X, thereby guaranteeing a physically meaningful dictionary and dimensionality reduction. We use l1;1 regularization to select the dictionary from the data and show this leads to an exact convex relaxation of l0 in the case of distinct noise free data. We also show how to relax the restriction-to-X constraint by initializing an alternating minimization approach with the solution of the convex model, obtaining a dictionary close to but not necessarily in X. We focus on applications of the proposed framework to hyperspectral end member and abundances identification and also show an application to blind source separation of NMR data.
Total variation regularization for fMRI-based prediction of behaviour by Vincent Michel,
Alexandre Gramfort Gaël Varoquaux ,
Evelyn Eger,
Bertrand Thirion. The abstract reads:
While medical imaging typically provides massive amounts of data, the extraction of relevant information for predictive diagnosis remains a difficult challenge. Functional MRI (fMRI) data, that provide an indirect measure of task-related or spontaneous neuronal activity, are classically analyzed in a mass-univariate procedure yielding statistical parametric maps. This analysis framework disregards some important principles of brain organization: population coding, distributed and overlapping representations. Multivariate pattern analysis, i.e., the prediction of behavioural variables from brain activation patterns better captures this structure. To cope with the high dimensionality of the data, the learning method has to be regularized. However, the spatial structure of the image is not taken into account in standard regularization methods, so that the extracted features are often hard to interpret. More informative and interpretable results can be obtained with the l_1 norm of the image gradient, a.k.a. its Total Variation (TV), as regularization. We apply for the first time this method to fMRI data, and show that TV regularization is well suited to the purpose of brain mapping while being a powerful tool for brain decoding. Moreover, this article presents the first use of TV regularization for classification.
by
Laurent Gosse. The abstract reads;
Efficient recovery of smooth functions which are $s$-sparse with respect to the base of so--called Prolate Spheroidal Wave Functions from a small number of random sampling points is considered. The main ingredient in the design of both the algorithms we propose here consists in establishing a uniform $L^\infty$ bound on the measurement ensembles which constitute the columns of the sensing matrix. Such a bound provides us with the Restricted Isometry Property for this rectangular random matrix, which leads to either the exact recovery property or the ``best $s$-term approximation" of the original signal by means of the $\ell^1$ minimization program. The first algorithm considers only a restricted number of columns for which the $L^\infty$ holds as a consequence of the fact that eigenvalues of the Bergman's restriction operator are close to 1 whereas the second one allows for a wider system of PSWF by taking advantage of a preconditioning technique. Numerical examples are spread throughout the text to illustrate the results.
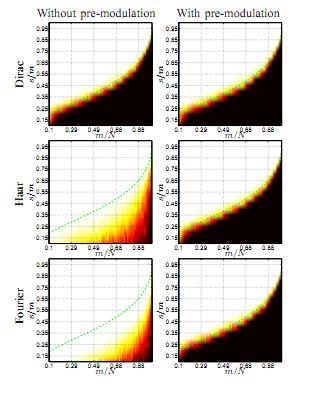
Sparsity Driven People Localization with a Heterogeneous Network of Cameras by
Alexandre Alahi,
Laurent Jacques,
Yannick Boursier and
Pierre Vandergheynst. The abstract
This paper addresses the problem of localizing people in low and high density crowds with a network of heterogeneous cameras. The problem is recasted as a linear inverse problem. It relies on deducing the discretized occupancy vector of people on the ground, from the noisy binary silhouettes observed as foreground pixels in each camera. This inverse problem is regularized by imposing a sparse occupancy vector, i.e. made of few non-zero elements, while a particular dictionary of silhouettes linearly maps these non-empty grid locations to the multiple silhouettes viewed by the cameras network. The proposed framework is (i) generic to any scene of people, i.e. people are located in low and high density crowds, (ii) scalable to any number of cameras and already working with a single camera, (iii) unconstraint on the scene surface to be monitored, and (iv) versatile with respect to the camera’s geometry, e.g. planar or omnidirectional. Qualitative and quantitative results are presented on the APIDIS and the PETS 2009 Benchmark datasets. The proposed algorithm successfully detects people occluding each other given severely degraded extracted features, while outperforming state-of-the-art people localization techniques.
Recent attention on performance analysis of singleuser multiple-input multiple-output (MIMO) systems has been on understanding the impact of the spatial correlation model on ergodic capacity. In most of these works, it is assumed that the statistical degrees of freedom (DoF) in the channel can be captured by decomposing it along a suitable eigen-basis and that the transmitter has perfect knowledge of the statistical DoF. With an increased interest in large-antenna systems in state-of-theart technologies, these implicit channel modeling assumptions in the literature have to be revisited. In particular, multi-antenna measurements have showed that large-antenna systems are sparse where only a few DoF are dominant enough to contribute towards capacity. Thus, in this work, it is assumed that the transmitter can only afford to learn the dominant statistical DoF in the channel. The focus is on understanding ergodic capacity scaling laws in sparse channels. Unlike classical results, where linear capacity scaling is implicit, sparsity of MIMO channels coupled with a knowledge of only the dominant DoF is shown to result in a new paradigm of sub-linear capacity scaling that is consistent with experimental results and physical arguments. It is also shown that uniform-power signaling over all the antenna dimensions is wasteful and could result in a significant penalty over optimally adapting the antenna spacings in response to the sparsity level of the channel and transmit SNR.
This paper addresses the problem of inferring sparse causal networks modeled by multivariate auto-regressive (MAR) processes. Conditions are derived under which the Group Lasso (gLasso) procedure consistently estimates sparse network structure. The key condition involves a “false connection score” . In particular, we show that consistent recovery is possible even when the number of observations of the network is far less than the number of parameters describing the network, provided that < 1. The false connection score is also demonstrated to be a useful metric of recovery in non-asymptotic regimes. The conditions suggest a modified gLasso procedure which tends to improve the false connection score and reduce the chances of reversing the direction of causal influence. Computational experiments and a real network based electrocorticogram (ECoG) simulation study demonstrate the effectiveness of the approach.
Abstract. This note demonstrates that it is possible to bound the expectation of an arbitrary norm of a random matrix drawn from the Stiefel manifold in terms of the expected norm of a standard Gaussian matrix with the same size. A related comparison holds for any convex function of a random matrix drawn from the Stiefel manifold. For certain norms, a reversed inequality is also valid.
Statistical Compressed Sensing of Gaussian Mixture Models by
Guoshen Yu,
Guillermo Sapiro. The abstract reads:
A novel framework of compressed sensing, namely statistical compressed sensing (SCS), that aims at efficiently sampling a collection of signals that follow a statistical distribution, and achieving accurate reconstruction on average, is introduced. SCS based on Gaussian models is investigated in depth. For signals that follow a single Gaussian model, with Gaussian or Bernoulli sensing matrices of O(k) measurements, considerably smaller than the O(k log(N/k)) required by conventional CS based on sparse models, where N is the signal dimension, and with an optimal decoder implemented via linear filtering, significantly faster than the pursuit decoders applied in conventional CS, the error of SCS is shown tightly upper bounded by a constant times the best k-term approximation error, with overwhelming probability. The failure probability is also significantly smaller than that of conventional sparsity-oriented CS. Stronger yet simpler results further show that for any sensing matrix, the error of Gaussian SCS is upper bounded by a constant times the best k-term approximation with probability one, and the bound constant can be efficiently calculated. For Gaussian mixture models (GMMs), that assume multiple Gaussian distributions and that each signal follows one of them with an unknown index, a piecewise linear estimator is introduced to decode SCS. The accuracy of model selection, at the heart of the piecewise linear decoder, is analyzed in terms of the properties of the Gaussian distributions and the number of sensing measurements. A maximum a posteriori expectation-maximization algorithm that iteratively estimates the Gaussian models parameters, the signals model selection, and decodes the signals, is presented for GMM-based SCS. In real image sensing applications, GMM-based SCS is shown to lead to improved results compared to conventional CS, at a considerably lower computational cost.
Since its emergence, compressive sensing (CS) has attracted many researchers' attention. In the CS, recovery algorithms play an important role. Basis pursuit (BP) and matching pursuit (MP) are two major classes of CS recovery algorithms. However, both BP and MP are originally designed for one-dimensional (1D) sparse signal recovery, while many practical signals are two-dimensional (2D), e.g. image, video, etc. To recover 2D sparse signals effectively, this paper develops the 2D orthogonal MP (2D-OMP) algorithm, which shares the advantages of low complexity and good performance. The 2D-OMP algorithm can be widely used in those scenarios involving 2D sparse signal processing, e.g. image/video compression, compressive imaging, etc.
by
Yilun Chen,
Alfred O. Hero III. The abstract reads:
We introduce a recursive adaptive group lasso algorithm for real-time penalized least squares prediction that produces a time sequence of optimal sparse predictor coefficient vectors. At each time index the proposed algorithm computes an exact update of the optimal $\ell_{1,\infty}$-penalized recursive least squares (RLS) predictor. Each update minimizes a convex but nondifferentiable function optimization problem. We develop an online homotopy method to reduce the computational complexity. Numerical simulations demonstrate that the proposed algorithm outperforms the $\ell_1$ regularized RLS algorithm for a group sparse system identification problem and has lower implementation complexity than direct group lasso solvers.
by
Rui Castro and
Robert Nowak. The introduction reads:
Consider the problem of estimating a signal from noisy samples. The conventional approach (e.g., Shannon-Nyquist sampling) is to sample at many locations in a non-adaptive and more-or-less uniform manner. For example, in a digital camera we collect samples at locations on a square lattice (each sample being a pixel). Under certain scenarios though there is an extra exibility, and an alternative and more versatile approach is possible: choose the sample locations `on-the-y', depending on the information collected up to that time. This is what we call adaptive sampling, as opposed to the conventional approach, referred to here as passive sampling. Although intuitively very appealing, adaptive sampling is seldom used because of the difficulty of design and analysis of such feedback techniques, especially in complex settings. The topic of adaptive sampling, or active learning as it is sometimes called, has attracted signi cant attention from various research communities, in particular in the elds of computer science and statistics. A large body of work exists proposing algorithmic ideas and methods [1, 2, 3, 4, 5], but unfortunately there are few performance guarantees for many of those methods. Further most of those results take place in very special or restricted scenarios (e.g., absence of noise or uncertainty, yielding perfect decisions). Under the adaptive sampling framework there are a few interesting theoretical results, some of which are presented here, namely the pioneering work of [6] regarding the estimation of step functions, that was later rediscovered in [7] using di erent algorithmic ideas and tools. Building on some of those ideas, the work in [8, 9, 10, 11] provides performance guarantees for function estimation under noisy conditions, for several function classes that are particularly relevant to signal processing and analysis. In this chapter we provide an introduction to adaptive sampling techniques for signal estimation, both in parametric and non-parametric settings. Note that the scenarios we consider do not have the Markovian structure inherent to the Markov Decision Processes (MDPs), that are the topic of many chapters in this book, and that the `actions' (sample locations, or whether or not to collect a sample) do not a ect the environment. Another major di erence between the active learning problems considered and the MDPs is that, in the former, the set of possible actions/sample locations is generally uncountable.
We consider spatially coupled code ensembles. A particular instance are convolutional LDPC ensembles. It was recently shown that, for transmission over the memoryless binary erasure channel, this coupling increases the belief propagation threshold of the ensemble to the maximum a-posteriori threshold of the underlying component ensemble. This paved the way for a new class of capacity achieving low-density parity check codes. It was also shown empirically that the same threshold saturation occurs when we consider transmission over general binary input memoryless channels. In this work, we report on empirical evidence which suggests that the same phenomenon also occurs when transmission takes place over a class of channels with memory. This is confirmed both by simulations as well as by computing EXIT curves.
by Shun Zhang,
Gensun Fang.. The abstract reads;
In this paper we study the Gelfand and Kolmogorov numbers of compact embeddings between weighted function spaces of Besov and Triebel-Lizorkin type with polynomial weights. The sharp estimates are determined in the non-limiting case where the quasi-Banach setting is included.
by Shun Zhang,
Gensun Fang. The abstract reads;
We mainly consider the asymptotic behaviour of the approximation, Gelfand and Kolmogorov numbers of the compact embeddings between weighted Besov spaces with a general class of weights. We determine the exact estimates in almost all nonlimiting cases where the quasi-Banach setting is included. At the end we present complete results on related widths in the case of polynomial weights with small perturbations, in particular the exact estimates for the case $\alpha = d/{p^*}>0$ therein.
We present an uncertainty relation for the representation of signals in two different general (possibly redundant or incomplete) signal sets. This uncertainty relation is relevant for the analysis of signals containing two distinct features each of which can be described sparsely in a suitable general signal set. Furthermore, the new uncertainty relation is shown to lead to improved sparsity thresholds for recovery of signals that are sparse in general dictionaries. Specifically, our results improve on the well-known $(1+1/d)/2$-threshold for dictionaries with coherence $d$ by up to a factor of two. Furthermore, we provide probabilistic recovery guarantees for pairs of general dictionaries that also allow us to understand which parts of a general dictionary one needs to randomize over to "weed out" the sparsity patterns that prohibit breaking the square-root bottleneck.
Credit: NASA/JPL/University of Arizona/USGS,
Gully with Bright Deposits, Mars.



 reviewed in the New Yorker Review of Books:
reviewed in the New Yorker Review of Books: