Neural Architecture Search discover efficient ConvNets that require much fewer parameters and use less computation. https://t.co/6a0GqfcpCY pic.twitter.com/R8M51neFW0— hardmaru (@hardmaru) 18 august 2017
to what David replied eventually (see the thread)
Here are the two papers:
We found that with deeper networks energy efficiency declines. Activation!/weight/intermediate variable access dominates over FLOPS— david moloney (@cto_movidius) 18 august 2017
Here are the two papers:
Learning Transferable Architectures for Scalable Image Recognition by Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le
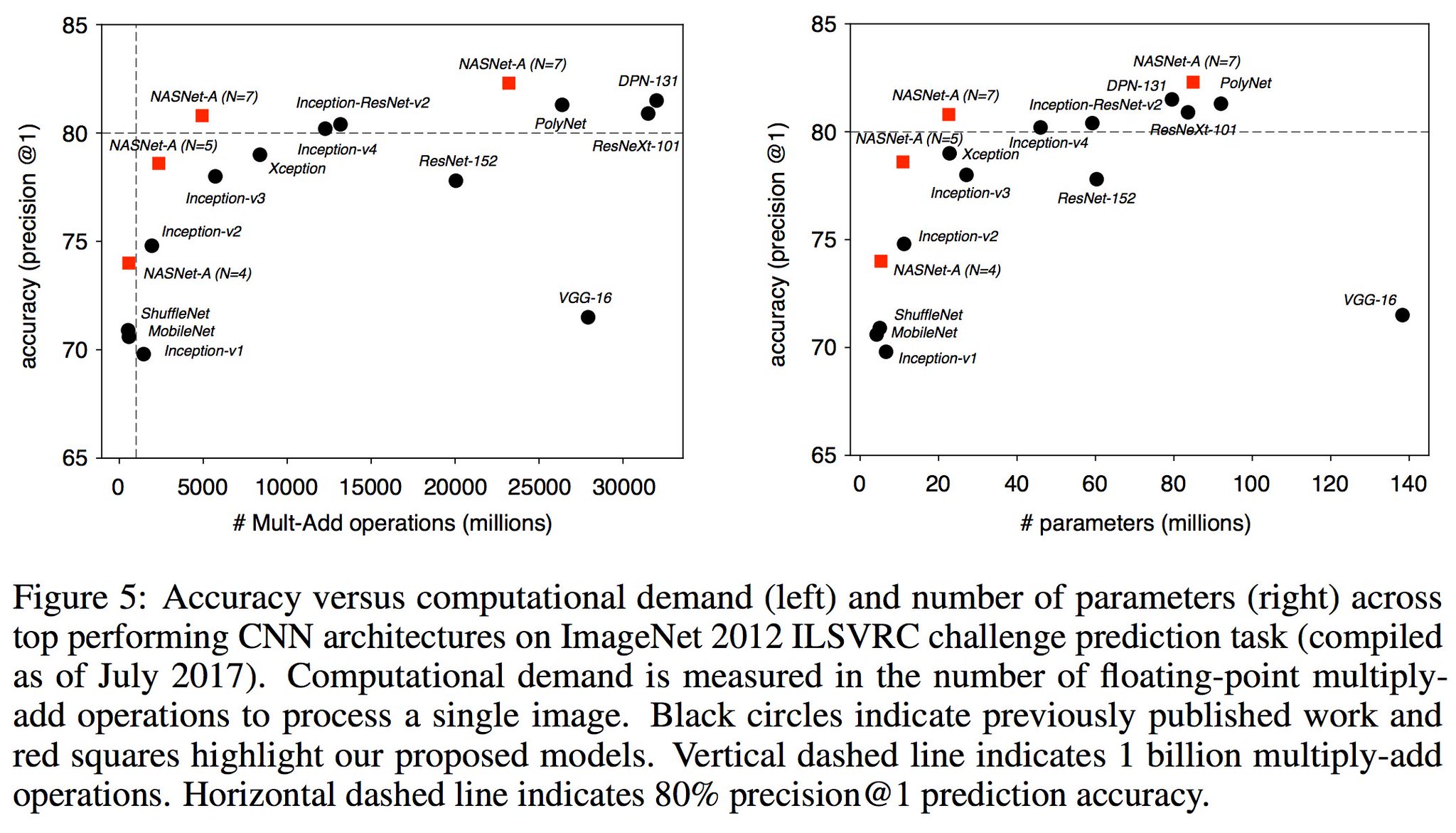
Developing state-of-the-art image classification models often requires significant architecture engineering and tuning. In this paper, we attempt to reduce the amount of architecture engineering by using Neural Architecture Search to learn an architectural building block on a small dataset that can be transferred to a large dataset. This approach is similar to learning the structure of a recurrent cell within a recurrent network. In our experiments, we search for the best convolutional cell on the CIFAR-10 dataset and then apply this learned cell to the ImageNet dataset by stacking together more of this cell. Although the cell is not learned directly on ImageNet, an architecture constructed from the best learned cell achieves state-of-the-art accuracy of 82.3% top-1 and 96.0% top-5 on ImageNet, which is 0.8% better in top-1 accuracy than the best human-invented architectures while having 9 billion fewer FLOPS. This cell can also be scaled down two orders of magnitude: a smaller network constructed from the best cell also achieves 74% top-1 accuracy, which is 3.1% better than the equivalently-sized, state-of-the-art models for mobile platforms.
 Liked this entry ? subscribe to Nuit Blanche's feed, there's more where that came from. You can also subscribe to Nuit Blanche by Email, explore the Big Picture in Compressive Sensing or the Matrix Factorization Jungle and join the conversations on compressive sensing, advanced matrix factorization and calibration issues on Linkedin.
Liked this entry ? subscribe to Nuit Blanche's feed, there's more where that came from. You can also subscribe to Nuit Blanche by Email, explore the Big Picture in Compressive Sensing or the Matrix Factorization Jungle and join the conversations on compressive sensing, advanced matrix factorization and calibration issues on Linkedin.
No comments:
Post a Comment