
This blog post was initially featured on Medium. At LightOn, we decided to start a blog and explain what can be done with the random projections performed by our Optical Processing Unit (OPU). Since most people think an optics based system can do only images, we decided to illustrate our technology on an NLP task. Here is the article:
This article is LightOn’s AI Research (LAIR) first contribution focused on applying LightOn’s Optical Processing Unit (OPU) hardware to generic large-scale Machine Learning tasks. Today we tackle the recently released public dataset of a nation-wide public debate and our first trial in using LightOn’s OPU for a Natural Language Processing task.
As a response to the “Gilets Jaunes” social unrest in France, President Emmanuel Macron declared the opening of a nation-wide citizen debate (“Grand Débat National”), as a way to collect the opinion of the French people on a number of subjects. Aside from public meetings taking place throughout the country, the “Grand Débat” took the form of an online platform where people could answer questions around four major themes: the environment, taxes, state organization, and democracy / citizenship. For every theme, the survey was divided in two parts: the first part featured multiple-choice surveys, while the second part included open-ended questions. A subset of the answers was made openly available by Etalab, the public organization responsible for the Open Data policy of the French government. The data can be found here.
The deadline for survey submissions to the “Grand Débat” was March 18 2019. The French government provided a first analysis on Monday, four days ago. At LightOn, we have been looking for applications of our Optical Processing Unit (OPU) to various Machine Learning problems including Natural Language Processing (NLP). We therefore took this opportunity to feature some exploratory tests on this new dataset. It should be emphasized that no one at LightOn is currently an expert in NLP: the goal of this article is only to demonstrate the kind of data processing that can be done using an OPU. We want to show how this can be done, in only a few days of work, and with no specific knowledge of NLP but a generic Machine Learning background.
The first NLP application of the OPU technology was to form sentence embeddings from word embeddings. Word embeddings are vector representation of words introduced in their modern form by Mikolov et al. (2013)¹. They have been extremely successful as a first step of virtually all NLP models: we replace vanilla one-hot-encoded vectors of dimension the size of the vocabulary with these typically 300-dimensional dense real-valued vectors. The space of word embeddings even has a sensible arithmetic, the classical example being KING — MAN + WOMAN = QUEEN. To obtain these embeddings, a linear neural network is trained to predict the surrounding words given the current word in a sliding window over a huge text corpus (this model is called skip-gram, predicting the current word from the context is also possible). At the end of the training, the projection columns of the weight matrix are the word embeddings. You can see it as a kind of shallow transfer learning, where only the first layer is pre-trained.
Sentence embeddings target similar representations, but for whole sentences. It is a much harder task than word embeddings because, while words are fixed entities and in finite and reasonable number (at least for a single language), sentences are compositional and sequential in nature. They have several degrees of freedom stemming from meaning, word choice, syntax, tone, length, etc. This diversity not only means that there is more information to encode, but also that it’s virtually impossible to save an embedding for every possible sentence. Sentence embeddings instead have to be formed on-the-fly from their constituent words.
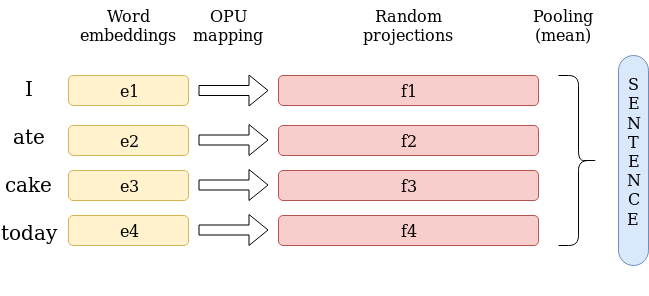
At the time of this writing, some of the leading models for sentence embeddings are SkipThought² and InferSent³. In particular, the paper that sparked our interest in sentence embeddings was the recent work of Wieting and Kiela (2019)⁴. This work shows that it is possible to obtain results on SentEval⁵ comparable to these advanced models with no training at all. One of the models used in this paper, Bag Of Random Embedding Projections(BOREP), uses random projections, which happens to be the operation an OPU excels at. As a result, we decided to give it a try. We followed BOREP but replaced the linear random projection with an OPU transform — complex-valued random projection followed by an element-wise non-linearity. The model is very simple: we get the embedding of each word in a sentence, we project it to a — much — higher dimension and then we apply a pooling function (the mean in practice) to obtain the embedding of the sentence.
The input to the current OPU prototypes -with remote access available to selected users - is a binary vector, meaning in this case that we need to use binary word embeddings. Since there is no such native embedding, we need to binarize real-valued word embeddings. For the latter, we chose fastText⁶, as it is among the best-performing word embedding method to date. To binarize the embeddings, we could use any standard binary encoding scheme. However it is hard to know a priori how destructive it would be for this kind of data. A possibly smarter thing to do is to train an autoencoder to do so. Luckily, some people did just that: binarize word embeddings using an autoencoder⁷. The associated github repo is in C, does not make use of a GPU and cannot handle large embeddings due to memory limitations, so we re-implemented it in PyTorch. It is hard to tell anything from the loss, so we evaluated our binary word embeddings directly on SentEval and obtained satisfying results for most tasks, except Semantic Textual Similarity (STS 12–16), for which there seems to be an unavoidable information loss. On a number of tasks, they performed even better than the original ones, probably because of their higher dimension. Indeed, the paper focuses on memory and computation savings, so the authors use rather low dimensional binary embeddings (up to 512 bits for an original dimension of 300 real numbers). Our goal is instead to obtain binary embeddings with the smallest possible information loss, so we went to much higher dimensions. Keep in mind that producing random projections on the OPU is essentially independent of the size — currently up to dimensions of 1 million ! In the end we used 3000 bits for each vector, so 10 bits per real number instead of 32, which seems reasonable.
Once this is done, we can actually use the OPU to form sentence embeddings using the aforementioned BOREP method. Evaluating it on SentEval gives satisfying results, in many tasks superior to that of the paper (even the Echo State Network). It should be noted that we didn’t find it useful to go above 15,000 dimensions, meaning that a high-end GPU could also have done the job in this case.
There are several reasons why increasing the dimensionality could increase performance on downstream tasks. The first is Cover’s theorem: projecting data non-linearly to a higher dimension increases the chance of them being linearly separable in the new high-dimensional space. This, of course, plays a role but the fact that a linear projection also improves performance in the Wieting and Kiela paper proves that simply adding parameters to the model already helps a lot. More interestingly, we can draw a parallel with work on hyperdimensional computing⁸. In very high-dimensional spaces (several thousand dimensions), the sheer volume available makes it possible to represent an entire dataset with no two points close to each other. The distances between two random points follow a very narrow Gaussian distribution: all points are more or less equidistant. In this setting, the mean of a few vectors is more similar to each of these vectors than any other point. The mean vector is then not merely a lossy summary of the original vectors but actually represents the set that contains them. We can thus expect the mean of the high-dimensional projections of the word embeddings to be truly more representative of the sentence than a mean computed in a lower-dimensional space, irrespective of the fact that the model used in downstream applications will have more parameters to accommodate this higher dimensionality.
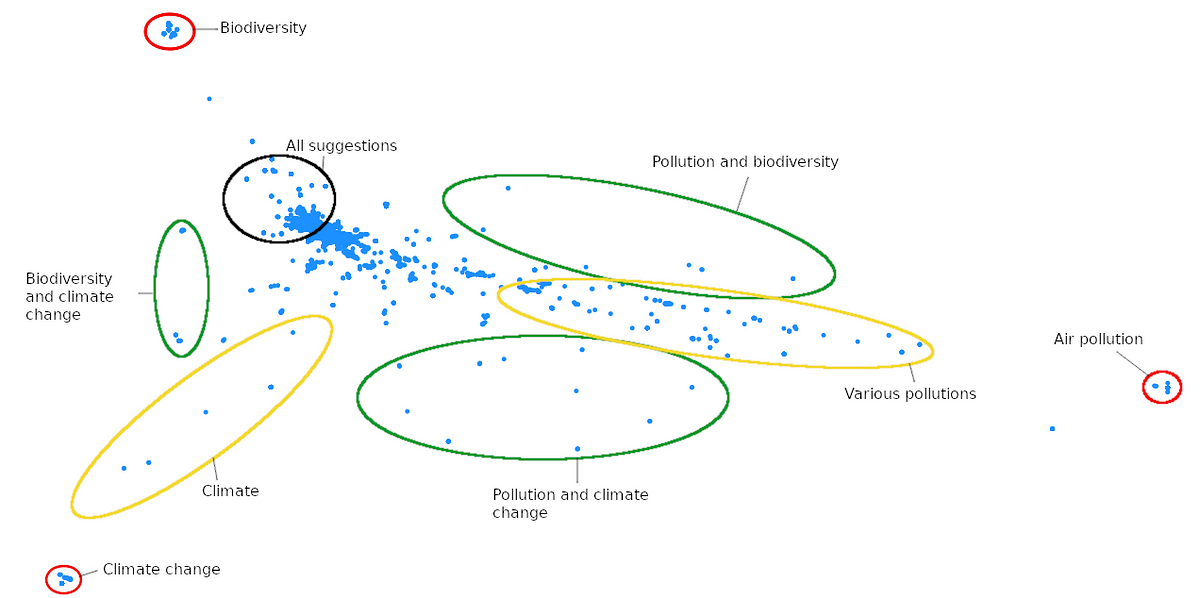
For our task of dealing with answers to open-ended questions, which is notoriously difficult, we decided that an interactive visualisation would be a nice way to explore the answers. The goal was to see clusters of similar answers as a summary of what people had to say on the matter. So we chose a specific question and formed an embedding for every answer as if it were a single sentence. From visual observations, if an answer contains several sentences, they are most of the time related, so grouping them seems a reasonable first-attempt assumption. We end up with almost a hundred thousand points in dimension 15,000 (which is also why going above 15,000 would have been problematic) and want to visualise them. A PCA to 2 or 3 dimensions doesn’t give a satisfying result, so we first keep the first 50 principal components and then use t-SNE⁹ do obtain a 2D representation of the data. The result exhibits some interesting patterns but upon inspection, we realize that the global structure doesn’t make much sense. Indeed, t-SNE only preserves local neighborhoods and loses any sense of global structure. Clusters of loosely similar answers are thus not close to each other and can even be on opposite sides of the graph. Increasing the perplexity of t-SNE is supposed to favor global structure over local one, but this had little effect, so we used another technique. t-SNE is an iterative, stochastic method requiring an initial projection. This initialization is usually random but it doesn’t have to. The first two principal components are the best 2D representation of the global structure of the data, so we use them (in practice taking the first two columns of the 50-component PCA we already computed) as the initial state of t-SNE. This allows us to preserve global structure while benefiting from the superior visualizing power of t-SNE. Follow this link to see an interactive version (in French) of this visualization. It only contains 10,000 answers, sampled uniformly without replacement, so that the interactivity remains smooth. Some annotated screenshots are shown just below. What you see are the answers to the first question of the “ecology” (environment) questionnaire. The question was:
What is to you the most important concrete problem regarding ecology ?
- Air pollution
- Biodiversity and species extinction
- Climate change
- Shore erosion
- Other: answer in plain text
It was a semi-open question with 4 suggested answers but also the possibility to write another answer in plain text if one was not satisfied with the suggestions. Very few people answered 4, so it does not stand out on the graph, but you can clearly see answers 1, 2 and 3 circled in red on the first graph. In green are answers that mentioned two of the suggested answers and in yellow answers that gave variations of one of the suggested answers, e.g. global warming instead of climate change or water pollution instead of air pollution. A significant portion of people refused to choose and said that all suggestions were equally important.
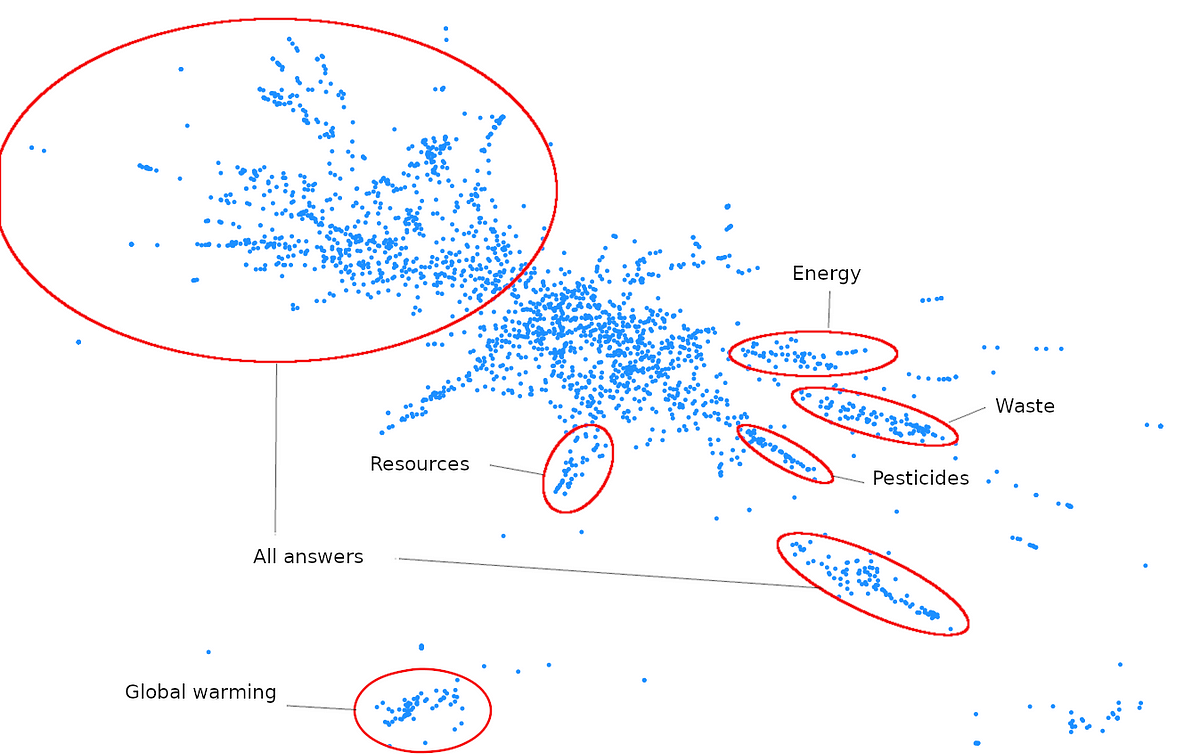
Our visualization technique mostly works with respect to our objective for short sentences, less for longer ones. These are instead gathered in the middle, where more groups can be found as you can see here:
Long answers are hard to classify as belonging to one group or another, and are likely to be far from any other answer, as mentioned before. We believe the big cloud in the middle to be an artifact of the projection, that gathers such isolated answers, more than of the embeddings.
Overall, the result is rather satisfying, given the time spent. There is, of course, much room for improvement, though, with at least three directions to explore:
- text preprocessing: we did tokenization, stop words removal and lemmatization, which are standard practices, but more thought could be put into it. For instance, a spelling corrector should help;
- multi-sentence answers: can we separate semantically independent parts of long answers to give them tags ? can we better combine the sentence embeddings of a multi-sentence answer than a simple average ?
- better sentence embeddings.
On the last point, one could, of course, use a more complex model than ours, e.g. SkipThought and InferSent. More recent models such as QuickThought¹⁰ or multi-task learning approaches have also been proposed¹¹ ¹². However, all these models are much harder to use than ours. Trained encoders are available in English but not in French, so one would have to retrain them. For supervised approaches, the data doesn’t even exist in French. SkipThought is unsupervised but takes several weeks to train. The best chance would be QuickThought but still it requires a book corpus in French and a day of training on a powerful GPU (a Titan X in the paper).
It is instead very easy to obtain satisfying results quickly with our model and OPU hardware. No training, any language works as long as word embeddings are available (fastText supports 157 languages), only the projection time (less than a minute in our case) and enough RAM to store the results are needed. The disadvantage is that the pooling function in our model loses word ordering information. The next step for us is therefore to try a time-aware model such as an Echo State Network, which was used with success in Wieting and Kiela (2019) and which can also be implemented very efficiently at large scale on an OPU¹³.
More info on LightOn’s OPU technology can be found at www.lighton.io. A remote access to an OPU through the LightOn Cloud can be granted, by invitation.
References
[1] Tomas Mikolov et al. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781 (2013).
[2] Ryan Kiros et al. “Skip-thought vectors.” Advances in Neural Information Processing Systems. 2015.
[3] Alexis Conneau et al. “Supervised learning of universal sentence representations from natural language inference data.” arXiv preprint arXiv:1705.02364 (2017).
[4] John Wieting and Douwe Kiela. “No training required: Exploring random encoders for sentence classification.” arXiv preprint arXiv:1901.10444 (2019).
[5] Alexis Conneau and Douwe Kiela. “Senteval: An evaluation toolkit for universal sentence representations.” arXiv preprint arXiv:1803.05449 (2018).
[6] Piotr Bojanowski et al. “Enriching word vectors with subword information. CoRR abs/1607.04606.” (2016).
[7] Julien Tissier, Guillaume Gravier and Amaury Habrard. “Near-lossless Binarization of Word Embeddings.” arXiv preprint arXiv:1803.09065 (2018).
[8] Pentti Kanerva “Hyperdimensional computing: An introduction to computing in distributed representation with high-dimensional random vectors.” Cognitive computation 1.2 (2009): 139–159.
[9] Laurens van der Maaten and Geoffrey Hinton. “Visualizing data using t-SNE.” Journal of Machine Learning Research 9.Nov (2008): 2579–2605.
[10] Lajanugen Logeswaran and Honglak Lee. “An efficient framework for learning sentence representations.” arXiv preprint arXiv:1803.02893 (2018).
[11] Sandeep Subramanian et al. “Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning.” CoRRabs/1804.00079 (2018): n. pag.
[12] Daniel Cer et al. “Universal sentence encoder.” arXiv preprint arXiv:1803.11175 (2018).
[13] Jonathan Dong et al. “Scaling up Echo-State Networks with multiple light scattering.” 2018 IEEE Statistical Signal Processing Workshop (2018), arXiv:1609.05204
The author François Boniface, Machine Learning R&D engineer at LightOn AI Research
Join the CompressiveSensing subreddit or the Facebook page and post there !
 Liked this entry ? subscribe to Nuit Blanche's feed, there's more where that came from. You can also subscribe to Nuit Blanche by Email, explore the Big Picture in Compressive Sensing or the Matrix Factorization Jungle and join the conversations on compressive sensing, advanced matrix factorization and calibration issues on Linkedin.
Liked this entry ? subscribe to Nuit Blanche's feed, there's more where that came from. You can also subscribe to Nuit Blanche by Email, explore the Big Picture in Compressive Sensing or the Matrix Factorization Jungle and join the conversations on compressive sensing, advanced matrix factorization and calibration issues on Linkedin.
No comments:
Post a Comment