What happens when you have to learn a lot of things ? Two ICLR papers seem to point to the need for equally big models with an implication on regularization or in sparsely using them.
Outrageously Lare Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer by Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton and Jeff Dean
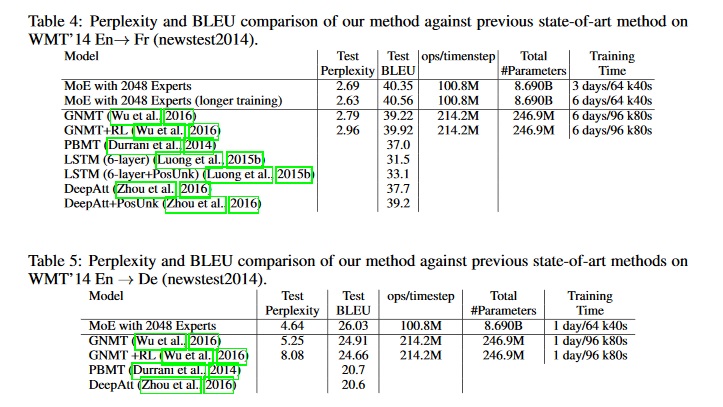
The capacity of a neural network to absorb information is limited by its number of parameters. In this work, we present a new kind of layer, the Sparsely-Gated Mixture-of-Experts (MoE), which can be used to effectively increase model capacity with only a modest increase in computation. This layer consists of up to thousands of feed-forward sub-networks (experts) containing a total of up to billions of parameters. A trainable gating network determines a sparse combination of these experts to use for each example. We apply the MoE to the task of language modeling, where model capacity is critical for absorbing the vast quantities of world knowledge available in the training corpora. We present new language model architectures where an MoE layer is inserted between stacked LSTMs, resulting in models with orders of magnitude more parameters than would otherwise be feasible. On language modeling and machine translation benchmarks, we achieve comparable or better results than state-of-the-art at lower computational cost, including test perplexity of 28.0 on the 1 Billion Word Language Modeling Benchmark and BLEU scores of 40.56 and 26.03 on the WMT’14 En to Fr and En to De datasets respectively.
In the second paper, we can note the following:
"Deep neural networks easily fit random labels...The effective capacity of neural networks is large enough for a brute-force memorization of the entire data set...."
Understanding Deep Learning Requires Re-Thinking Generalization by Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, Oriol Vinyals
Despite their massive size, successful deep artificial neural networks can exhibit a remarkably small difference between training and test performance. Conventional wisdom attributes small generalization error either to properties of the model family, or to the regularization techniques used during training. Through extensive systematic experiments, we show how these traditional approaches fail to explain why large neural networks generalize well in practice. Specifically, our experiments establish that state-of-the-art convolutional networks for image classification trained with stochastic gradient methods easily fit a random labeling of the training data. This phenomenon is qualitatively unaffected by explicit regularization, and occurs even if we replace the true images by completely unstructured random noise. We corroborate these experimental findings with a theoretical construction showing that simple depth two neural networks already have perfect finite sample expressivity as soon as the number of parameters exceeds the number of data points as it usually does in practice. We interpret our experimental findings by comparison with traditional models.
 Liked this entry ? subscribe to Nuit Blanche's feed, there's more where that came from. You can also subscribe to Nuit Blanche by Email, explore the Big Picture in Compressive Sensing or the Matrix Factorization Jungle and join the conversations on compressive sensing, advanced matrix factorization and calibration issues on Linkedin.
Liked this entry ? subscribe to Nuit Blanche's feed, there's more where that came from. You can also subscribe to Nuit Blanche by Email, explore the Big Picture in Compressive Sensing or the Matrix Factorization Jungle and join the conversations on compressive sensing, advanced matrix factorization and calibration issues on Linkedin.
No comments:
Post a Comment