Shallow and Deep Learning for Audio and Natural Language Processing by Po-Sen Huang
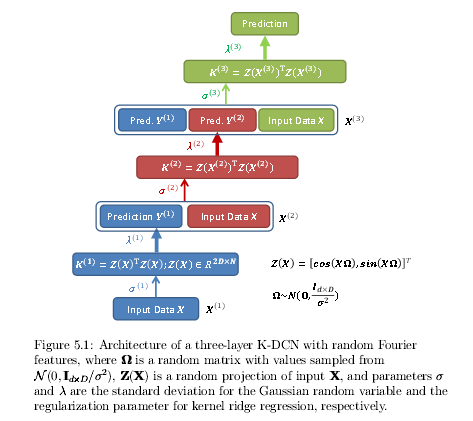
Many machine learning algorithms can be viewed as optimization problems that seek the optimum hypothesis in a hypothesis space. To model the complex dependencies in real-world arti cial intelligence tasks, machine learning algorithms are required to have high expressive power (high degrees of freedom or richness of a family of functions) and a large amount of training data. Deep learning models and kernel machines are regarded as models with high expressive power through the composition of multiple layers of nonlinearities and through nonlinearly mapping data to a high-dimensional space, respectively. While the majority of deep learning work is focused on pure classi cation problems given input data, there are many other challenging Artificial Intelligence (AI) problems beyond classi cation tasks. In real-world applications, there are cases where we have structured relationships between and among input data and output targets, which have not been fully taken into account in deep learning models. On the other hand, though kernel machines involve convex optimization and have strong theoretical grounding in tractable optimization techniques, for large-scale applications, kernel machines often suffer from signi cant memory requirements and computational expense. Resolving the computational limitation and thereby enhancing the expressibility of kernel machines are important for large-scale real-world applications. Learning models based on deep learning and kernel machines for audio and natural language processing tasks are developed in this dissertation. In particular, we address the challenges for deep learning with structured relationships among data and the computational limitations of large-scale kernel machines. A general framework is proposed to consider the relationship among output predictions and enforce constraints between a mixture input and output predictions for monaural source separation tasks. To model the structured relationships among inputs, the deep structured semantic models are introduced for an information retrieval task. Queries and documents are modeled as inputs to the deep learning models and the relevance is measured through the similarity at the output layer. A discriminative objective function is proposed to exploit the similarity and dissimilarity between queries and web documents. To address the scalability and e ciency of large-scale kernel machines, using deep architectures, ensemble models, and a scalable parallel solver are investigated to further scale-up kernel machines approximated by randomized feature maps. The proposed techniques are shown to match the expressive power of deep neural network based models in spoken language understanding and speech recognition tasks.
 Liked this entry ? subscribe to Nuit Blanche's feed, there's more where that came from. You can also subscribe to Nuit Blanche by Email, explore the Big Picture in Compressive Sensing or the Matrix Factorization Jungle and join the conversations on compressive sensing, advanced matrix factorization and calibration issues on Linkedin.
Liked this entry ? subscribe to Nuit Blanche's feed, there's more where that came from. You can also subscribe to Nuit Blanche by Email, explore the Big Picture in Compressive Sensing or the Matrix Factorization Jungle and join the conversations on compressive sensing, advanced matrix factorization and calibration issues on Linkedin.
No comments:
Post a Comment