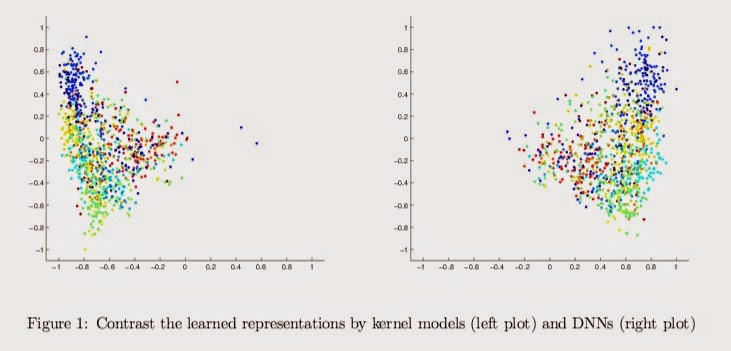
How to Scale Up Kernel Methods to Be As Good As Deep Neural Nets by Zhiyun Lu, Avner May, Kuan Liu, Alireza Bagheri Garakani, Dong Guo, Aurélien Bellet, Linxi Fan, Michael Collins, Brian Kingsbury, Michael Picheny, Fei Sha
In this paper, we investigate how to scale up kernel methods to take on large-scale problems, on which deep neural networks have been prevailing. To this end, we leverage existing techniques and develop new ones. These techniques include approximating kernel functions with features derived from random projections, parallel training of kernel models with 100 million parameters or more, and new schemes for combining kernel functions as a way of learning representations. We demonstrate how to muster those ideas skillfully to implement large-scale kernel machines for challenging problems in automatic speech recognition. We valid our approaches with extensive empirical studies on real-world speech datasets on the tasks of acoustic modeling. We show that our kernel models are equally competitive as well-engineered deep neural networks (DNNs). In particular, kernel models either attain similar performance to, or surpass their DNNs counterparts. Our work thus avails more tools to machine learning researchers in addressing large-scale learning problems.
 Liked this entry ? subscribe to Nuit Blanche's feed, there's more where that came from. You can also subscribe to Nuit Blanche by Email, explore the Big Picture in Compressive Sensing or the Matrix Factorization Jungle and join the conversations on compressive sensing, advanced matrix factorization and calibration issues on Linkedin.
Liked this entry ? subscribe to Nuit Blanche's feed, there's more where that came from. You can also subscribe to Nuit Blanche by Email, explore the Big Picture in Compressive Sensing or the Matrix Factorization Jungle and join the conversations on compressive sensing, advanced matrix factorization and calibration issues on Linkedin.
No comments:
Post a Comment