This week we have quite a few interesting papers on top of the ones I have already mentioned. I am also having some difficulty trying to parse whether we have some compressive sensing problem or some matrix factorization one. The latter will be the subject of a different entry. Enjoy!
First a presentation by
Rémi Gribonval entitled
Sparsity & Co.:An Overview of Analysis vs Synthesis in Low-Dimensional Signal Models that features some actual experimental work with compressive sensing.
There is afterwards a mix of Arxiv. NIPS'11 and other papers:
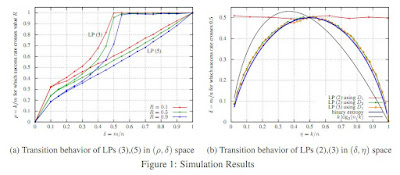
We consider a system of m linear equations in n variables Ax=b where A is a given m x n matrix and b is a given m-vector known to be equal to Ax' for some unknown solution x' that is integer and k-sparse: x' in {0,1}^n and exactly k entries of x' are 1. We give necessary and sufficient conditions for recovering the solution x exactly using an LP relaxation that minimizes l1 norm of x. When A is drawn from a distribution that has exchangeable columns, we show an interesting connection between the recovery probability and a well known problem in geometry, namely the k-set problem. To the best of our knowledge, this connection appears to be new in the compressive sensing literature. We empirically show that for large n if the elements of A are drawn i.i.d. from the normal distribution then the performance of the recovery LP exhibits a phase transition, i.e., for each k there exists a value m' of m such that the recovery always succeeds if m > m' and always fails if m < m'. Using the empirical data we conjecture that m' = nH(k/n)/2 where H(x) = -(x)log_2(x) - (1-x)log_2(1-x) is the binary entropy function.
If you recall a
similar limit was also attained by the
EM-BG-AMP solver of
Jeremy Vila and
Phil Schniter
On the error of estimating the sparsest solution of underdetermined linear systems by
Massoud Babaie-Zadeh,
Christian Jutten,
Hosein Mohimani. The abstract reads:
Let A be an n by m matrix with m>n, and suppose that the underdetermined linear system As=x admits a sparse solution s0 for which ||s0||_0 < 1/2 spark(A). Such a sparse solution is unique due to a well-known uniqueness theorem. Suppose now that we have somehow a solution s_hat as an estimation of s0, and suppose that s_hat is only `approximately sparse', that is, many of its components are very small and nearly zero, but not mathematically equal to zero. Is such a solution necessarily close to the true sparsest solution? More generally, is it possible to construct an upper bound on the estimation error ||s_hat-s0||_2 without knowing s0? The answer is positive, and in this paper we construct such a bound based on minimal singular values of submatrices of A. We will also state a tight bound, which is more complicated, but besides being tight, enables us to study the case of random dictionaries and obtain probabilistic upper bounds. We will also study the noisy case, that is, where x=As+n. Moreover, we will see that where ||s0||_0 grows, to obtain a predetermined guaranty on the maximum of ||s_hat-s0||_2, s_hat is needed to be sparse with a better approximation. This can be seen as an explanation to the fact that the estimation quality of sparse recovery algorithms degrades where ||s0||_0 grows.
Target Detection Performance Bounds in Compressive Imaging by
Kalyani Krishnamurthy,
Rebecca Willett,
Maxim Raginsky. The abstract reads:
This paper describes computationally efficient approaches and associated theoretical performance guarantees for the detection of known targets and anomalies from few projection measurements of the underlying signals. The proposed approaches accommodate signals of different strengths contaminated by a colored Gaussian background, and perform detection without reconstructing the underlying signals from the observations. The theoretical performance bounds of the target detector highlight fundamental tradeoffs among the number of measurements collected, amount of background signal present, signal-to-noise ratio, and similarity among potential targets coming from a known dictionary. The anomaly detector is designed to control the number of false discoveries. The proposed approach does not depend on a known sparse representation of targets; rather, the theoretical performance bounds exploit the structure of a known dictionary of targets and the distance preservation property of the measurement matrix. Simulation experiments illustrate the practicality and effectiveness of the proposed approaches.
We develop mask iterative hard thresholding algorithms (mask IHT and mask DORE) for sparse image reconstruction of objects with known contour. The measurements follow a noisy underdetermined linear model common in the compressive sampling literature. Assuming that the contour of the object that we wish to reconstruct is known and that the signal outside the contour is zero, we formulate a constrained residual squared error minimization problem that incorporates both the geometric information (i.e. the knowledge of the object's contour) and the signal sparsity constraint. We first introduce a mask IHT method that aims at solving this minimization problem and guarantees monotonically non-increasing residual squared error for a given signal sparsity level. We then propose a double overrelaxation scheme for accelerating the convergence of the mask IHT algorithm. We also apply convex mask reconstruction approaches that employ a convex relaxation of the signal sparsity constraint. In X-ray computed tomography (CT), we propose an automatic scheme for extracting the convex hull of the inspected object from the measured sinograms; the obtained convex hull is used to capture the object contour information. We compare the proposed mask reconstruction schemes with the existing large-scale sparse signal reconstruction methods via numerical simulations and demonstrate that, by exploiting both the geometric contour information of the underlying image and sparsity of its wavelet coefficients, we can reconstruct this image using a significantly smaller number of measurements than the existing methods.
While compressed sensing (CS) based reconstructions have been developed for low-dose CBCT, a clear understanding on the relationship between the image quality and imaging dose at low dose levels is needed. In this paper, we qualitatively investigate this subject in a comprehensive manner with extensive experimental and simulation studies. The basic idea is to plot image quality and imaging dose together as functions of number of projections and mAs per projection over the whole clinically relevant range. A clear understanding on the tradeoff between image quality and dose can be achieved and optimal low-dose CBCT scan protocols can be developed for various imaging tasks in IGRT. Main findings of this work include: 1) Under the CS framework, image quality has little degradation over a large dose range, and the degradation becomes evident when the dose < 100 total mAs. A dose < 40 total mAs leads to a dramatic image degradation. Optimal low-dose CBCT scan protocols likely fall in the dose range of 40-100 total mAs, depending on the specific IGRT applications. 2) Among different scan protocols at a constant low-dose level, the super sparse-view reconstruction with projection number less than 50 is the most challenging case, even with strong regularization. Better image quality can be acquired with other low mAs protocols. 3) The optimal scan protocol is the combination of a medium number of projections and a medium level of mAs/view. This is more evident when the dose is around 72.8 total mAs or below and when the ROI is a low-contrast or high-resolution object. Based on our results, the optimal number of projections is around 90 to 120. 4) The clinically acceptable lowest dose level is task dependent. In our study, 72.8mAs is a safe dose level for visualizing low-contrast objects, while 12.2 total mAs is sufficient for detecting high-contrast objects of diameter greater than 3 mm.
The sparse signal recovery in standard compressed sensing (CS) requires that the sensing matrix be known a priori. The CS problem subject to perturbation in the sensing matrix is often encountered in practice and results in the literature have shown that the signal recovery error grows linearly with the perturbation level. This paper assumes a structure for the perturbation. Under mild conditions on the perturbed sensing matrix, it is shown that a sparse signal can be recovered by $\ell_1$ minimization with the recovery error being at most proportional to the measurement noise level, similar to that in the standard CS. The recovery is exact in the special noise free case provided that the signal is sufficiently sparse with respect to the perturbation level. A similar result holds for compressible signals under an additional assumption of small perturbation. Algorithms are proposed for implementing the $\ell_1$ minimization problem and numerical simulations are carried out that verify our analysis.
I've talked to
David and he tells me that he is using dictionary coming from a background of sparse recovery. In CS we generally make a difference between the measurement matrix and the dictionary. In his case, the measurement matrix is the identity.
Sparse Estimation with Structured Dictionaries by
David P. Wipf. The abstract reads:
In the vast majority of recent work on sparse estimation algorithms, performance has been evaluated using ideal or quasi-ideal dictionaries (e.g., random Gaussian or Fourier) characterized by unit 2 norm, incoherent columns or features. But in reality, these types of dictionaries represent only a subset of the dictionaries that are actually used in practice (largely restricted to idealized compressive sensing applications). In contrast, herein sparse estimation is considered in the context of structured dictionaries possibly exhibiting high coherence between arbitrary groups of columns and/or rows. Sparse penalized regression models are analyzed with the purpose of finding, to the extent possible, regimes of dictionary invariant performance. In particular, a Type II Bayesian estimator with a dictionarydependent sparsity penalty is shown to have a number of desirable invariance properties leading to provable advantages over more conventional penalties such as the 1 norm, especially in areas where existing theoretical recovery guarantees no longer hold. This can translate into improved performance in applications such as model selection with correlated features, source localization, and compressive sensing with constrained measurement directions.
Dimensionality Reduction Using the Sparse Linear Model by
Ioannis Gkioulekas Todd Zickler. The abstract reads:
We propose an approach for linear unsupervised dimensionality reduction, based on the sparse linear model that has been used to probabilistically interpret sparse coding. We formulate an optimization problem for learning a linear projection from the original signal domain to a lower-dimensional one in a way that approximately preserves, in expectation, pairwise inner products in the sparse domain. We derive solutions to the problem, present nonlinear extensions, and discuss relations to compressed sensing. Our experiments using facial images, texture patches, and images of object categories suggest that the approach can improve our ability to recover meaningful structure in many classes of signals.
The attendant project page is
here.
In this paper, we consider the problem of compressed sensing where the goal is to recover almost all sparse vectors using a small number of fixed linear measurements. For this problem, we propose a novel partial hard-thresholding operator that leads to a general family of iterative algorithms. While one extreme of the family yields well known hard thresholding algorithms like ITI and HTP[17, 10], the other end of the spectrum leads to a novel algorithm that we call Orthogonal Matching Pursuit with Replacement (OMPR). OMPR, like the classic greedy algorithm OMP, adds exactly one coordinate to the support at each iteration, based on the correlation with the current residual. However, unlike OMP, OMPR also removes one coordinate from the support. This simple change allows us to prove that OMPR has the best known guarantees for sparse recovery in terms of the Restricted Isometry Property (a condition on the measurement matrix). In contrast, OMP is known to have very weak performance guarantees under RIP. Given its simple structure, we are able to extend OMPR using locality sensitive hashing to get OMPR-Hash, the first provably sub-linear (in dimensionality) algorithm for sparse recovery. Our proof techniques are novel and flexible enough to also permit the tightest known analysis of popular iterative algorithms such as CoSaMP and Subspace Pursuit. We provide experimental results on large problems providing recovery for vectors of size up to million dimensions. We demonstrate that for large-scale problems our proposed methods are more robust and faster than existing methods.
We consider the problem of recovering the parameter R K of a sparse function f (i.e. the number of non-zero entries of is small compared to the number K of features) given noisy evaluations of f at a set of well-chosen sampling points. We introduce an additional randomization process, called Brownian sensing, based on the computation of stochastic integrals, which produces a Gaussian sensing matrix, for which good recovery properties are proven, independently on the number of sampling points N , even when the features are arbitrarily non-orthogonal. Under the assumption that f is Holder continuous with exponent at least 1 / 2 , we provide an estimate of the parameter such that - 2 = O ( 2 / N ) , where is the observation noise. The method uses a set of sampling points uniformly distributed along a one-dimensional curve selected according to the features. We report numerical experiments illustrating our method.
On the accuracy of -filtering of signals with block-sparse structure by
Anatoli Juditsky,
Fatma Kılınc Karzan,
Arkadi Nemirovski,
Boris Polyak. The abstract reads:
We discuss new methods for the recovery of signals with block-sparse structure, based on 1 -minimization. Our emphasis is on the efficiently computable error bounds for the recovery routines. We optimize these bounds with respect to the method parameters to construct the estimators with improved statistical properties. We justify the proposed approach with an oracle inequality which links the properties of the recovery algorithms and the best estimation performance.
Finding optimal sparse solutions to estimation problems, particularly in underdetermined regimes has recently gained much attention. Most existing literature study linear models in which the squared error is used as the measure of discrepancy to be minimized. However, in many applications discrepancy is measured in more general forms such as loglikelihood. Regularization by `1-norm has been shown to induce sparse solutions, but their sparsity level can be merely suboptimal. In this paper we present a greedy algorithm, dubbed Gradient Support Pursuit (GraSP), for sparsity-constrained optimization. Quantifiable guarantees are provided for GraSP when cost functions have the “Stable Hessian Property”.
The attendant presentation is
here.
Clinical imaging with structural MRI routinely relies on multiple acquisitions of the same region of interest under several different contrast preparations. This work presents a reconstruction algorithm based on Bayesian compressed sensing to jointly reconstruct a set of images from undersampled kspace data with higher fidelity than when the images are reconstructed either individually or jointly by a previously proposed algorithm, M-FOCUSS. The joint inference problem is formulated in a hierarchical Bayesian setting, wherein solving each of the inverse problems corresponds to finding the parameters (here, image gradient coefficients) associated with each of the images. The variance of image gradients across contrasts for a single volumetric spatial position is a single hyperparameter. All of the images from the same anatomical region, but with different contrast properties, contribute to the estimation of the hyperparameters, and once they are found, the k-space data belonging to each image are used independently to infer the image gradients. Thus, commonality of image spatial structure across contrasts is exploited without the problematic assumption of correlation across contrasts. Examples demonstrate improved reconstruction quality (up to a factor of 4 in root-mean-square error) compared with previous compressed sensing algorithms and show the benefit of joint inversion under a hierarchical Bayesian model.

by
Sehoon Lim,
Daniel L. Marks, and
David J. Brady. The abstract reads:
Compressive holography applies sparsity priors to data acquired by digital holography to infer a small number of object features or basis vectors from a slightly larger number of discrete measurements. Compressive holography may be applied to reconstruct three-dimensional (3D) images from two-dimensional (2D) measurements or to reconstruct 2D images from sparse apertures. This paper is a tutorial covering practical compressive holography procedures, including field propagation, reference filtering, and inverse problems in compressive holography. We present as examples 3D tomography from a 2D hologram, 2D image reconstruction from a sparse aperture, and diffuse object estimation from diverse speckle realizations.
of interest is the presentation on
Experimental Demonstrations of Compressive Holography
Sharp RIP Bound for Sparse Signal and Low-Rank Matrix Recovery by
Tony Cai and
Anru Zhang. The abstract reads:
This paper establishes a sharp condition on the restrict isometry property (RIP) for both the sparse signal recovery and low-rank matrix recovery. It is shown that if the measurement matrix A satisfies the RIP condition δAk <1/3, then all k-sparse signals β can be recovered exactly via the constrained l1 minimization based on y = Aβ. Similarly, if the linear map M satisfies the RIP condition δMr <1/3, then all matricesX of rank at most r can be recovered exactly via the constrained nuclear norm minimization based on b = M(X). Furthermore, in both cases it is not possible to do so in general when the condition does not hold. In addition, noisy cases are considered and oracle inequalities are given under the sharp RIP condition.
of related interest:
Given a subset K of the unit Euclidean sphere, we estimate the minimal number m = m(K) of hyperplanes that generate a uniform tessellation of K, in the sense that the fraction of the hyperplanes separating any pair x; y 2 K is nearly proportional to the Euclidean distance between x and y. Random hyperplanes prove to be almost ideal for this problem; they achieve the almost optimal bound m = O(w(K)2) where w(K) is the Gaussian mean width of K. Using the map that sends x 2 K to the sign vector with respect to the hyperplanes, we conclude that every bounded subset K of Rn embeds into the Hamming cube f1; 1gm with a small distortion in
the Gromov-Haussdor metric. Since for many sets K one has m = m(K) n, this yields a new discrete mechanism of dimension reduction for sets in Euclidean spaces.
Diffuse Imaging: Creating Optical Images With Unfocused Time-Resolved Illumination and Sensing by
Ahmed Kirmani, Haris Jeelani,
Vahid Montazerhodjat, and
Vivek K Goyal, . The abstract reads:
Conventional imaging uses steady-state illumination and light sensing with focusing optics; variations of the light field with time are not exploited. We develop a signal processing framework for estimating the reflectance of a Lambertian planar surface in a known position using omnidirectional, time-varying illumination and unfocused, time-resolved sensing in place of traditional optical elements such as lenses and mirrors. Our model associates time sampling of the intensity of light incident at each sensor with a linear functional of . The discrete-time samples are processed to obtain -regularized estimates of . Improving on previous work, using nonimpulsive, bandlimited light sources instead of impulsive illumination significantly improves signal-tonoise ratio (SNR) and reconstruction quality. Our simulations suggest that practical diffuse imaging applications may be realized with commercially-available temporal light intensity modulators and sensors used in standard optical communication systems.

 Liked this entry ? subscribe to Nuit Blanche's feed, there's more where that came from. You can also subscribe to Nuit Blanche by Email, explore the Big Picture in Compressive Sensing or the Matrix Factorization Jungle and join the conversations on compressive sensing, advanced matrix factorization and calibration issues on Linkedin.
Liked this entry ? subscribe to Nuit Blanche's feed, there's more where that came from. You can also subscribe to Nuit Blanche by Email, explore the Big Picture in Compressive Sensing or the Matrix Factorization Jungle and join the conversations on compressive sensing, advanced matrix factorization and calibration issues on Linkedin.




