The spectrum of algorithm and hardware to approximate the identity was recently featured in a Quick Panorama of Sensing from Direct Imaging to Machine Learning and one of the main issue as we go toward indirect imaging is the ability to perform certain operations Faster Than a Blink of an Eye. Here is a new attempt at using a relatively simple model of neural network borrowing operations performed from compressive sensing.
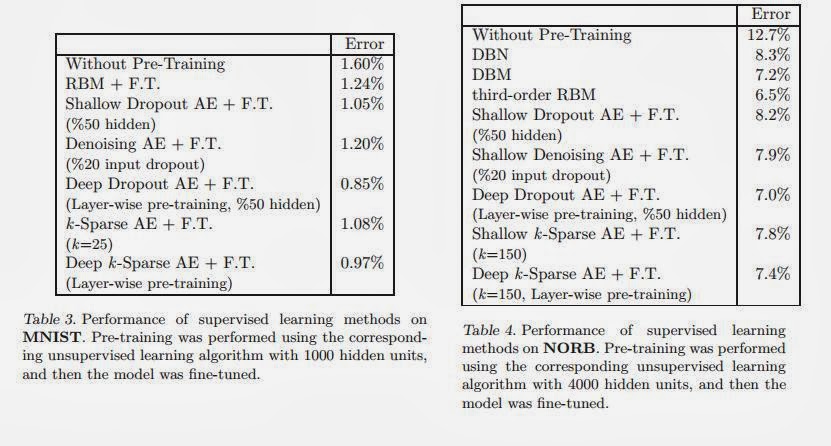
Recently, it has been observed that when representations are learnt in a way that encourages sparsity, improved performance is obtained on classification tasks. These methods involve combinations of activation functions, sampling steps and different kinds of penalties. To investigate the effectiveness of sparsity by itself, we propose the k-sparse autoencoder, which is a linear model, but where in hidden layers only the k highest activities are kept. When applied to the MNIST and NORB datasets, we find that this method achieves better classification results than denoising autoencoders, networks trained with dropout, and restricted Boltzmann machines. k-sparse autoencoders are simple to train and the encoding stage is very fast, making them well-suited to large problem sizes, where conventional sparse coding algorithms cannot be applied.
Looks like a simple implementation that really seems to follow the steps of an actual IHT implementation with sparse constraints on the coefficient during the iteration and this reminds me of [1]. Let us note that the scores to beat for fine tuned implementations are:
- for the MNIST dataset: 0.23%
- for the NORB dataset: 2.53%
both records held by the same group. More on that later.
[1] Convergence of a Neural Network for Sparse Approximation using the Nonsmooth Łojasiewicz Inequality by Aurele Balavoine, Christopher Rozell, Justin Romberg
 Liked this entry ? subscribe to Nuit Blanche's feed, there's more where that came from. You can also subscribe to Nuit Blanche by Email, explore the Big Picture in Compressive Sensing or the Matrix Factorization Jungle and join the conversations on compressive sensing, advanced matrix factorization and calibration issues on Linkedin.
Liked this entry ? subscribe to Nuit Blanche's feed, there's more where that came from. You can also subscribe to Nuit Blanche by Email, explore the Big Picture in Compressive Sensing or the Matrix Factorization Jungle and join the conversations on compressive sensing, advanced matrix factorization and calibration issues on Linkedin.
No comments:
Post a Comment